GAN的来源
2014年Goodfellow提出Generative Adversarial Nets即生成式对抗网络,它要解决的问题是如何从训练样本中学习出新样本,训练样本是图片就生成新图片,训练样本是文章就输出新文章等等。
GANs简单的想法就是用两个模型, 一个生成模型,一个判别模型。判别模型用于判断一个给定的图片是不是真实的图片(从数据集里获取的图片),生成模型的任务是去创造一个看起来像真的图片一样的图片,有点拗口,就是说模型自己去产生一个图片,可以和你想要的图片很像。而在开始的时候这两个模型都是没有经过训练的,这两个模型一起对抗训练,生成模型产生一张图片去欺骗判别模型,然后判别模型去判断这张图片是真是假,最终在这两个模型训练的过程中,两个模型的能力越来越强,最终达到稳态。
GAN的基本组成
GAN 模型中的两位博弈方分别由生成式模型(Generative Model)和判别式模型(Discriminative Model)充当。
生成模型: G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越像真实样本越好;
判别模型: D 是一个二分类器,估计一个样本来自于训练数据(而非生成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率。
可以做如下类比:生成网络 G 好比假币制造团伙,专门制造假币,判别网络 D 好比警察,专门检测使用的货币是真币还是假币,G 的目标是想方设法生成和真币一样的货币,使得 D 判别不出来,D 的目标是想方设法检测出来 G 生成的假币。
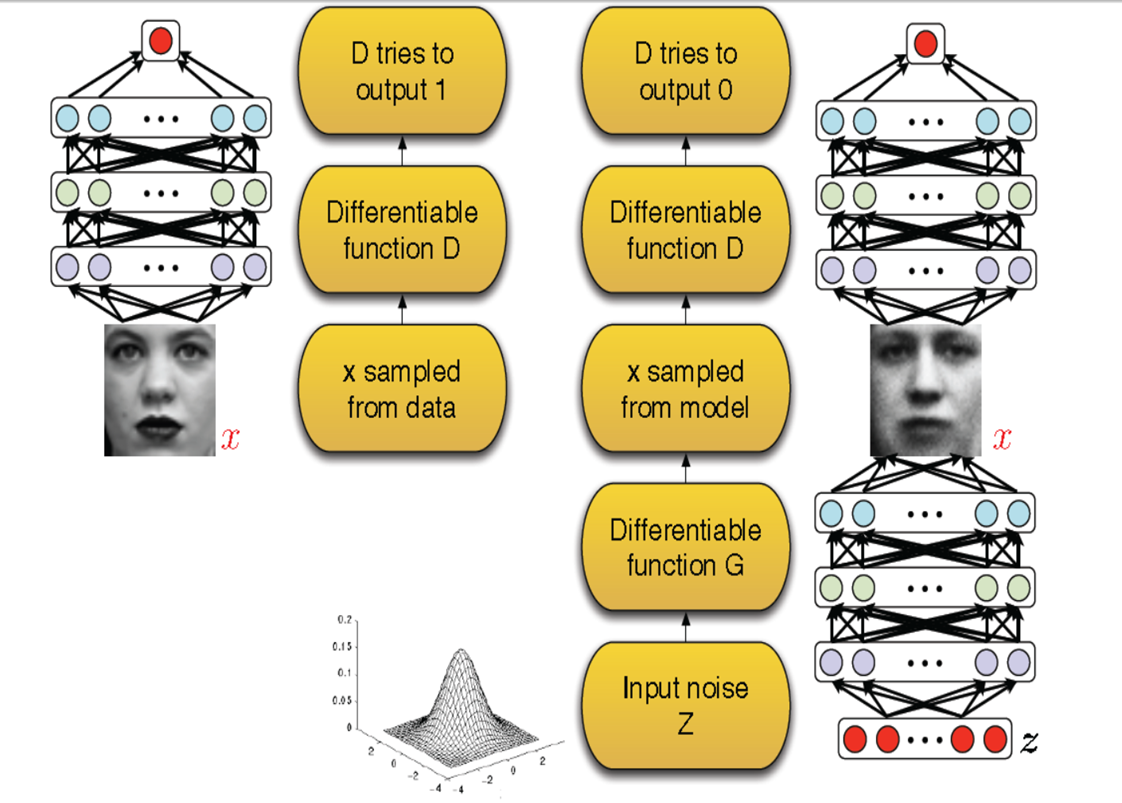
上图是GAN网络的流程图,我们用1代表真实数据,0来代表生成的假数据。对于判别器D来说,对于真实数据,它要尽可能让判别器输出值为1;而对于生成器G,根据随机噪音向量z生成假数据也输入判别器D,使得判别器输出假数据的值为1是生成器的目标,而对于这些假数据,判别器要尽可能输出0。
GAN的训练过程可以看成一个博弈的过程,也可以看成2个人在玩一个极大极小值游戏,可以用如下公式表示:
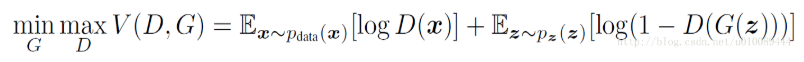
其本质上是两个优化问题,把拆解就如同下面两个公式,上面是优化D的,下面是优化G的。
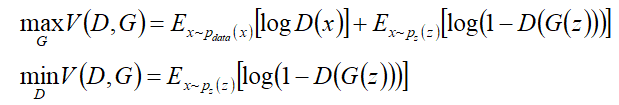
当优化D时,生成器确定,我们要让判别器尽可能输出高的值,所以要最大化公式(2)的值;当优化G的时候,判别器确定,我们要使判别器判断错误,尽可能使D(G(z))的值更大,所以要最小化公式(3)的值。
GAN的训练过程
下图为GAN的训练过程。
生成式对抗网络主要由生成器G和判别器D组成,训练过程如下所述:
- 输入噪声(隐藏变量)Z
- 通过生成器G得到x_fake=G(z)
- 从真实数据集中获取一部分真实数据x_real
- 将两者混合x=x_fake+x_real
- 将数据喂入判别部分D,给定标签x_fake=0,x_real=1,这一过程就是简单的二分类
- 按照分类结果,回传loss
在整个过程中,D要尽可能的使D(G(z))=0,D(x_real)=1(火眼金睛,不错杀也不漏杀)。而G则要使得D(G(z))=1(即让生成的图片以假乱真)
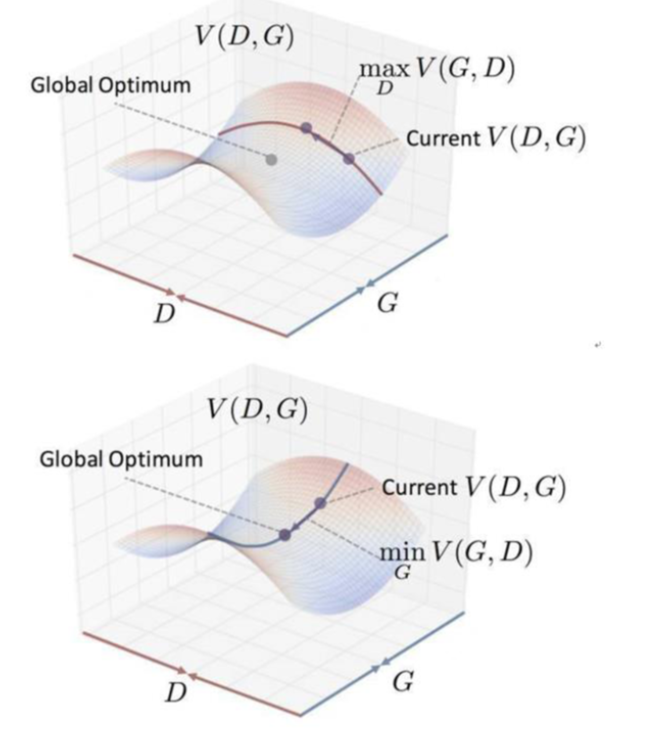
GAN的算法流程和动态求解过程如下图所示:
一开始我们确定G,最大化D,让点沿着D变大的方向移动(红色箭头),然后我们确定D,最小化G,让点沿着G变小的方向移动(蓝色箭头)。循环上述若干步后,达到期望的鞍点(理想最优解)。

GAN的网络结构
判别器(卷积)
卷积层大家应该都很熟悉了,为了方便说明,定义如下:
- 二维的离散卷积(N=2)
- 方形的特征输入(i1=i2=i)
- 方形的卷积核尺寸(k1=k2=k )
- 每个维度相同的步长(s1=s2=s)
- 每个维度相同的padding (p1=p2=p)
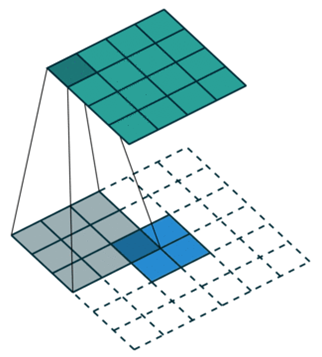
下图(左)表示参数为 (i=5,k=3,s=2,p=1)的卷积计算过程,从计算结果可以看出输出特征的尺寸为 (o1=o2=o=3);下图(右)表示参为 (i=6,k=3,s=2,p=1)的卷积计算过程,从计算结果可以看出输出特征的尺寸为 (o1=o2=o=3)。
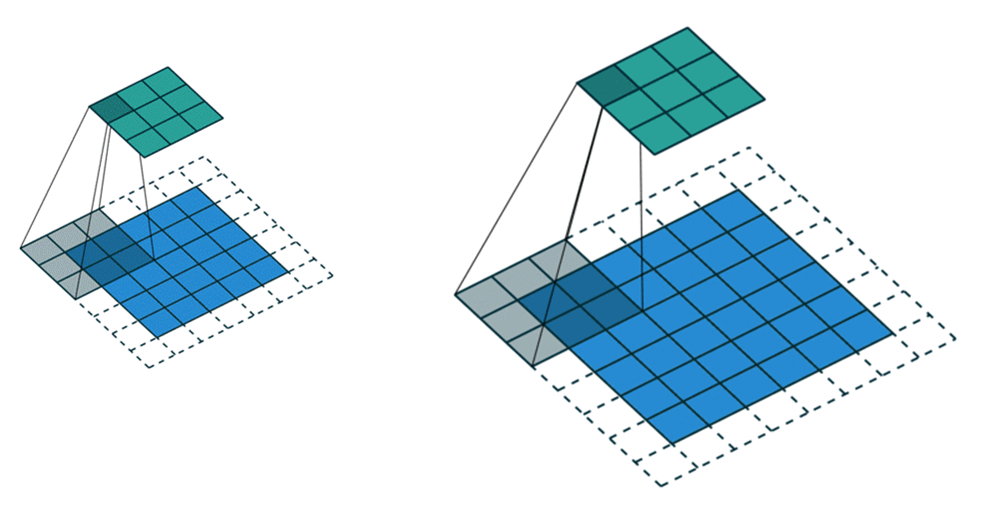
从上述2个例子我们可以总结出卷积层输入特征和输出特征尺寸和卷积核参数的关系为:
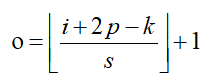
生成器(反卷积)
在介绍反卷积之前,我们先来看一下卷积运算和矩阵运算之间的关系。例有如下运算(i=4,k=3,s=1,p=0),输出为o=2。对于上述卷积运算,我们把上图所示的3x3卷积核展开成一个如下图所示的[4.16]的稀疏矩阵C,其中非0元素Wi,j表示卷积核的第i行和第j列。

我们再把4x4的输入特征展开成[16,1]的矩阵X,那么Y=CX则是一个[4,1]的输出特征矩阵,把它重新排列成2x2的输出特征就得到最终的结果,从上述分析可以看出卷积层的计算其实是可以转化成矩阵相乘的。值得注意的是,在一些深度学习网络的开源框架中,并不是通过这种转换方法来计算卷积的,因为这个转换会存在很多无用的0乘操作,caffe中具体实现卷积计算的方法可以参考impleming convolution as a matrix multiplication。
通过上述的分析,我们已经知道卷积层的前向操作可以表示为和矩阵C相乘,那么我们很容易得到卷积层的反向传播就是和C的转置相乘。
反卷积和卷积的关系如下
反卷积又称transposed(转置) convolution,我们可以看出其实卷积层的前向传播过程就是反卷积层的反向传播过程,卷积层的反向传播过程就是反卷积层的前向传播过程。因为卷积层的前向反向计算分别为乘C和CT,而反卷积层的前向反向计算分别为乘CT和(CT)T,所以他们的前向传播和反向传播刚好交换过来。
同样为了说明,定义反卷积操作参数如下:
- 二维的离散卷积(N=2)
- 方形的特征输入(i1‘=i2‘=i‘)
- 方形的卷积核尺寸(k1‘=k2‘=k‘)
- 每个维度相同的步长(s1‘=s2‘=s‘)
- 每个维度相同的padding (p1‘=p2‘=p‘)
上图表示的是参数为( i′=2,k′=3,s′=1,p′=2)的反卷积操作,其对应的卷积操作参数为 (i=4,k=3,s=1,p=0)。我们可以发现对应的卷积和非卷积操作其 (k=k′,s=s′),但是反卷积却多了p′=2。通过对比我们可以发现卷积层中左上角的输入只对左上角的输出有贡献,所以反卷积层会出现 p′=k−p−1=2。通过示意图,我们可以发现,反卷积层的输入输出在 s=s′=1的情况下关系为: o′=i′-k′+2p′+1=i′+(k-1)-2p
GAN的优点
- GAN是一种生成式模型,相比较其他生成模型(玻尔兹曼机和GSNs)只用到了反向传播
- 相比其他所有模型, GAN可以产生更加清晰,真实的样本
- GAN采用的是一种无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域
GAN的缺点
- 训练GAN需要达到纳什均衡,有时候可以用梯度下降法做到,有时候做不到.我们还没有找到很好的达到纳什均衡的方法,所以训练GAN相比VAE或者PixelRNN是不稳定的
- GAN不适合处理离散形式的数据,比如文本
- GAN存在训练不稳定、梯度消失、模式崩溃的问题
实例DCGAN网络
网络结构 (判别器)
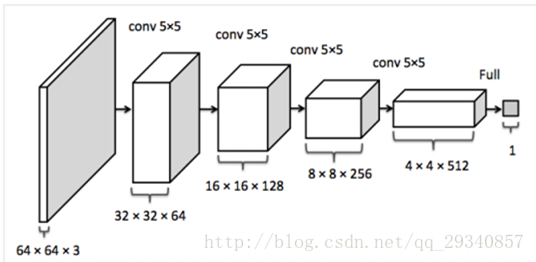
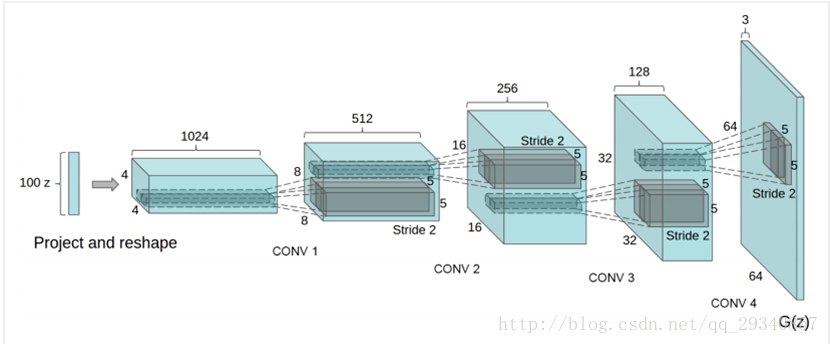
网络结构 (生成器)
二次元动漫人脸(共50个epoch)
数据集:51223张动漫人脸,图左为原始数据集,图右为训练过程
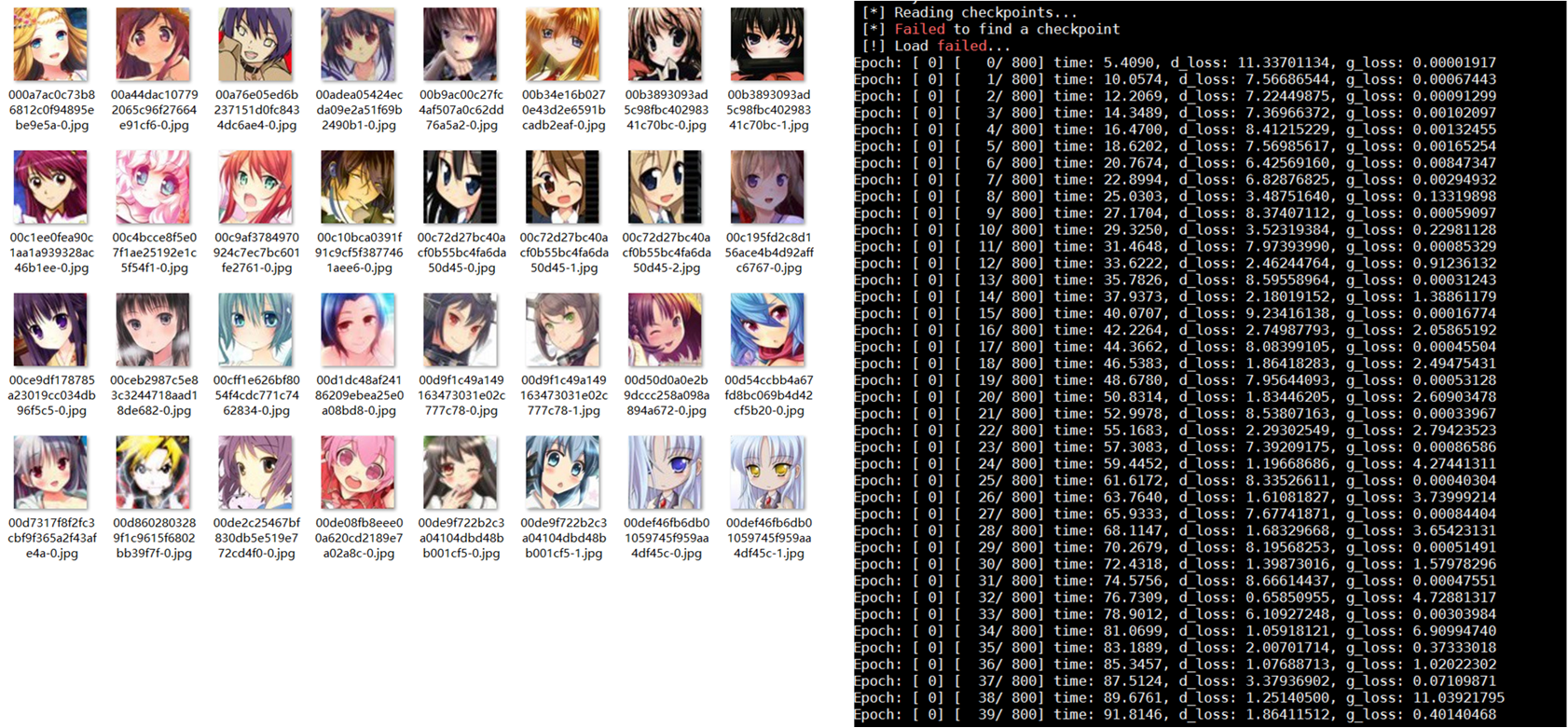
训练过程生成效果图如下:

真实人脸(共100个epoch)
数据集:CelebA 是香港中文大学的开放数据集,包含10,177个名人身份的202,599张人脸图片。(选取了25600张),数据集如下:
训练过程生成效果图如下


